前几天学习了并查集和trie树,这里总结一下trie。 本文讨论一棵最简单的trie树,基于英文26个字母组成的字符串,讨论插入字符串、判断前缀是否存在、查找字符串等基本操作;至于trie树的删除单个节点实在是少见,故在此不做详解。
l Trie原理
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
l Trie性质
好多人说trie的根节点不包含任何字符信息,我所习惯的trie根节点却是包含信息的,而且认为这样也方便,下面说一下它的性质 (基于本文所讨论的简单trie树)
1. 字符的种数决定每个节点的出度,即branch数组(空间换时间思想)
2. branch数组的下标代表字符相对于a的相对位置
3. 采用标记的方法确定是否为字符串。
4. 插入、查找的复杂度均为O(len),len为字符串长度
l Trie的示意图
如图所示,该trie树存有abc、d、da、dda四个字符串,如果是字符串会在节点的尾部进行标记。没有后续字符的branch分支指向NULL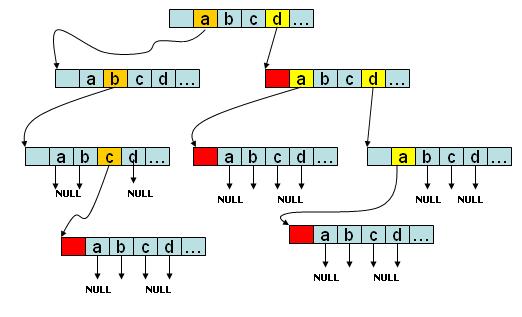 l TrieTrie的优点举例
l TrieTrie的优点举例
已知n个由小写字母构成的平均长度为10的单词,判断其中是否存在某个串为另一个串的前缀子串。下面对比3种方法:
1. 最容易想到的:即从字符串集中从头往后搜,看每个字符串是否为字符串集中某个字符串的前缀,复杂度为O(n^2)。
2. 使用hash:我们用hash存下所有字符串的所有的前缀子串。建立存有子串hash的复杂度为O(n*len)。查询的复杂度为O(n)* O(1)= O(n)。
3. 使用trie:因为当查询如字符串abc是否为某个字符串的前缀时,显然以b,c,d....等不是以a开头的字符串就不用查找了。所以建立trie的复杂度为O(n*len),而建立+查询在trie中是可以同时执行的,建立的过程也就可以成为查询的过程,hash就不能实现这个功能。所以总的复杂度为O(n*len),实际查询的复杂度只是O(len)。
解释一下hash为什么不能将建立与查询同时执行,例如有串:911,911456输入,如果要同时执行建立与查询,过程就是查询911,没有,然后存入9、91、911,查询911456,没有然后存入9114、91145、911456,而程序没有记忆功能,并不知道911在输入数据中出现过。所以用hash必须先存入所有子串,然后for循环查询。
而trie树便可以,存入911后,已经记录911为出现的字符串,在存入911456的过程中就能发现而输出答案;倒过来亦可以,先存入911456,在存入911时,当指针指向最后一个1时,程序会发现这个1已经存在,说明911必定是某个字符串的前缀,该思想是我在做pku上的3630中发现的,详见本文配套的“入门练习”。
l Trie的简单实现(插入、查询)


1 2 #include3 using namespace std; 4 5 const int branchNum = 26; //声明常量 6 int i; 7 struct Trie_node 8 { 9 bool isStr; //记录此处是否构成一个串。10 Trie_node *next[branchNum];//指向各个子树的指针,下标0-25代表26字符11 Trie_node():isStr(false)12 {13 memset(next,NULL,sizeof(next));14 }15 };16 17 class Trie18 {19 public:20 Trie();21 void insert(const char* word);22 bool search(char* word); 23 void deleteTrie(Trie_node *root);24 private:25 Trie_node* root;26 };27 28 Trie::Trie()29 {30 root = new Trie_node();31 }32 33 void Trie::insert(const char* word)34 {35 Trie_node *location = root;36 while(*word)37 {38 if(location->next[*word-'a'] == NULL)//不存在则建立39 {40 Trie_node *tmp = new Trie_node();41 location->next[*word-'a'] = tmp;42 } 43 location = location->next[*word-'a']; //每插入一步,相当于有一个新串经过,指针要向下移动44 word++;45 }46 location->isStr = true; //到达尾部,标记一个串47 }48 49 bool Trie::search(char *word)50 {51 Trie_node *location = root;52 while(*word && location)53 {54 location = location->next[*word-'a'];55 word++;56 }57 return(location!=NULL && location->isStr);58 }59 60 void Trie::deleteTrie(Trie_node *root)61 {62 for(i = 0; i < branchNum; i++)63 {64 if(root->next[i] != NULL)65 {66 deleteTrie(root->next[i]);67 }68 }69 delete root;70 }71 72 void main() //简单测试73 {74 Trie t;75 t.insert("a"); 76 t.insert("abandon");77 char * c = "abandoned";78 t.insert(c);79 t.insert("abashed");80 if(t.search("abashed"))81 printf("true\n");82 }
入门练习 :
转自:Cherish_yimi ()